I consider Wireshark one of the most successful FLOSS projects, and it outperforms
many tools in the field of packet capture (USB sniffing is one of my favorite
example), it is certainly the best tool I know for packet analysis, supportes by
its many protocol-specific plugins called dissector. These fast little C/C++
libraries do one thing, and do that well by extracting all available information
from packets of a certain protocol in a robust way.
In case of every network-related problem, Wireshark is one of the top three
tools I use, since the analysis of network traffic provides an invaluable
insight. This was also the case while I was experimenting with oursql,
which provides Python bindings for libmysqlclient, the native MySQL client
library, as an alternative to MySQLdb. While latter emulates client-side
parameter interpolation (as JDBC does it too), former exploits the
server-side prepared statements available since at least MySQL 4.0 (released
in August 2002). The problem with Wireshark was that although it had
dissector support for MySQL packets, dissection of COM_EXECUTE packets
resulted in the following message.
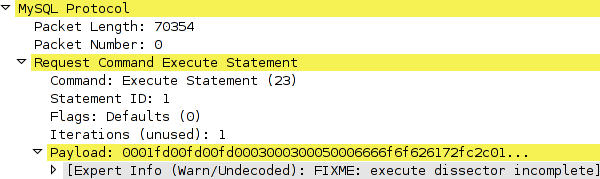
As the documentation of the MySQL ClientServer protocol states,
COM_EXECUTE packets depend on information exchanged upon preparing the
statement, which means that the dissector needed to be transformed to be
stateful. It seemed that the original author of the MySQL dissector started
working on the problem but then decided to leave it in an incomplete state.
To become familiar with the development of Wireshark, I started with the
flags field of the COM_EXECUTE packet. The documentation linked above
states, that although it was reserved for future use in MySQL 4.0, in later
versions, it carries a meaningful value. However, the dissector always decoded
the field with MySQL 4.0, regardless of the version actually used.
At first, I just added a new decoder and submitted
a patch in the Wireshark Bug Database that decoded the four possible
values according to the protocol documentation. Bill Meier took a look at it,
and asked whether I could change the behaviour to treat version 4 and 5
differently, offering pointers with regard to storing per-connection data,
effectively making the dissector stateful. I improved the patch and it
finally made it into SVN.
Knowing this, I started implementing the dissection of the fields left, namely
null_bit_map, new_parameter_bound_flag, type and values. The difficulty
was that the lenght and/or offset of these packets depended on the number of
placeholders sent during preparing the statement and also the number and index
of parameters that were bound by binary streaming (COM_LONG_DATA packets).
Since there already was a GHashTable member named smtms declared in the
mysql_conn_data struct of per-connection data, and it was initialized upon
the start of dissection and destroyed upon MYSQL_STMT_CLOSE and MYSQL_QUIT,
and a my_stmt_data struct was declared with an nparam member, I just
filled in the gaps by storing the number of parameters for every packet
received in response to a COM_PREPARE.
diff --git a/packet-mysql.c b/packet-mysql.c
index 3adc116..9c71409 100644
--- a/packet-mysql.c
+++ b/packet-mysql.c
@@ -1546,15 +1546,22 @@ mysql_dissect_row_packet(tvbuff_t *tvb, int offset, proto_tree *tree)
static int
mysql_dissect_response_prepare(tvbuff_t *tvb, int offset, proto_tree *tree, mysql_conn_data_t *conn_data)
{
+ my_stmt_data_t *stmt_data;
+ gint stmt_id;
+
/* 0, marker for OK packet */
offset += 1;
proto_tree_add_item(tree, hf_mysql_stmt_id, tvb, offset, 4, ENC_LITTLE_ENDIAN);
+ stmt_id = tvb_get_letohl(tvb, offset);
offset += 4;
proto_tree_add_item(tree, hf_mysql_num_fields, tvb, offset, 2, ENC_LITTLE_ENDIAN);
conn_data->stmt_num_fields = tvb_get_letohs(tvb, offset);
offset += 2;
proto_tree_add_item(tree, hf_mysql_num_params, tvb, offset, 2, ENC_LITTLE_ENDIAN);
conn_data->stmt_num_params = tvb_get_letohs(tvb, offset);
+ stmt_data = se_alloc(sizeof(struct my_stmt_data));
+ stmt_data->nparam = conn_data->stmt_num_params;
+ g_hash_table_replace(conn_data->stmts, &stmt_id, stmt_data);
offset += 2;
/* Filler */
offset += 1;
Later, I figured it out that using the GUI results in packets of the
captured buffers being dissected in an undeterministic order and count, which
could lead to problems, if the MYSQL_STMT_CLOSE packet was dissected before
the COM_PREPARE, so I removed the destruction of the hashtable.
Having the hashtable filled with the number of parameters for each statement,
I could make the dissector ignore the null_bit_map and decode the
new_parameter_bound_flag. Former is unnecessary since NULL values are
present as NULL typed parameters, while latter helps deciding whether the
packet should contain values of not. If parameters are expected, the ones that
are streamed are obviously not present in the COM_EXECUTE packet, which
required the following modifications to be made.
- The
my_stmt_data struct was extended with a guint8* param_flags member.
- Upon receiving a prepare response (and allocating the
my_stmt_data struct), an array of 8-bit unsinged integers (guint8) was allocated and all bytes were set to 0.
- During the dissection of a
MYSQL_STMT_SEND_LONG_DATA packet, a specific bit of the matching byte in the param_flags array was set.
- The dissector logic of
COM_EXECUTE ignored packets that had the corresponding bit set.
All that's left was the dissection of actual values, which were less documented
as most software depend on official MySQL code for client functionality.
Because of this (and for testing purposes, too) I tried several programming
languages and MySQL client libraries and captured the network traffic generated.
Among these were
- PHP (mysqli with libmysqlclient),
- Python (oursql with libmysqlclient),
- C (native libmysqlclient) and
- Java (JDBC with MySQL Connector/J).
One of the things that wasn't mentioned anywhere was the way strings were
encoded. First, I sent foobar in itself and the bytes reached the wire
were "\x06foobar" which meant that the length of the string was encoded
in the first byte. Next, I sent 300 characters and saw that the first byte
was 0xfc and then came the length of the string in two bytes. Finally, I
sent 66000 characters and got another magic character, 0xfd followed by
the length of the string in three bytes. (Luckily, Wireshark has 24-bit
little-endian integer read functionality built-in.) Another surprise was
that more than one field type codes were encoded in the same way:
0xf6 (NEWDECIMAL), 0xfc (BLOB), 0xfd (VAR_STRING) and 0xfe (STRING) are all strings encoded in the manner described above.0x07 (TIMESTAMP), 0x0a (DATE) and 0x0c (DATETIME) are all timestamps consisting of a calendar date and an optional time part.
At last, after many test captures, I managed to decode 15 different types with
10 different dissector algorithms. A const struct was created to keep the
type-dissector mapping simple and extensible.
typedef struct mysql_exec_dissector {
guint8 type;
guint8 unsigned_flag;
void (*dissector)(tvbuff_t *tvb, int *param_offset, proto_item *field_tree);
} mysql_exec_dissector_t;
static const mysql_exec_dissector_t mysql_exec_dissectors[] = {
{ 0x01, 0, mysql_dissect_exec_tiny },
{ 0x02, 0, mysql_dissect_exec_short },
{ 0x03, 0, mysql_dissect_exec_long },
{ 0x04, 0, mysql_dissect_exec_float },
{ 0x05, 0, mysql_dissect_exec_double },
{ 0x06, 0, mysql_dissect_exec_null },
...
{ 0xfe, 0, mysql_dissect_exec_string },
{ 0x00, 0, NULL },
};
I submitted the resulting patch in the Wireshark Bug Database, and Jeff
Morriss pointed out the obvious memory leak caused by the removal of the
hashtable destruction. He was very constructive, and told me about se_tree
structures which provide the subset of GHashtable functionality I needed but
are managed by the Wireshark memory manager, so no destruction was needed.
After I modified my patch accordingly, it got accepted and
finally made in into SVN. Here's an example screenshot how a successfully
dissected MySQL COM_EXECUTE packet might look like in the new version.
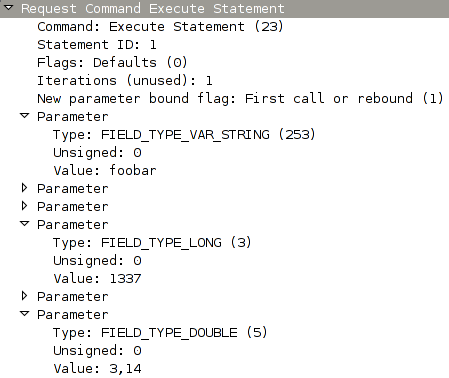
I hope you found this little story interesting, and maybe learned a thing
or two about the way Wireshark and/or MySQL works. The task I accomplished
required little previous knowledge in either of them, so all I can recommend is
if you see an incomplete or missing dissector in Wireshark, check out the
source code and start experimenting. Happy hacking!