Lately I analyzed a closed-source proprietary thick client application that rolled its own cryptography, including the one used for the network layer. To aid the protocol analysis, I needed two tools with a shared input. The input was the flow of packets sent and received by the application, which I first tried to extract using the hex output of tshark, but I realized that it displayed data from layers above TCP I didn't need, and on the other hand, it didn't perform TCP reassembly, which I didn't want to do by hand or reinventing the wheel.
So I decided to use the output of the Follow TCP stream function of
Wireshark, in hex mode to be precise. It can be saved to a plain text
file with a single click, and it just had what I needed: offsets and easily
parseable hex data. I've written a simple parser based on regular expressions
that could read such file, starting by defining the actual expressions. The
first one matches a single line, starting with whitespace in case of packets
sent, and nothing if received (group 1). This is followed by a hex offset
of the row (group 2), the row data encoded in 1 to 16 hex bytes (group 3),
and the ASCII dump of the row data. Latter is padded, so by limiting group 3
to 49 characters, it could be ignored effectively. I used the re.I flag so
I didn't have to write a-fA-F everywhere instead of a-f explicitly.
import re
FLOW_ROW_RE = re.compile(r'^(\s*)([0-9a-f]+)\s+([0-9a-f\s]{1,49})', re.I)
NON_HEX_RE = re.compile(r'[^0-9a-f]', re.I)
The Flow class itself is a list of entries, so I made the class inherit
from list and added a custom constructor. I also added an inner class called
Entry for the entries and two constants to indicate packet directions.
I used a namedtuple to provide some formality over using a dict.
The constructor expects the name of a file from Wireshark, opens it and
populates the list using the parent constructor and a generator function
called load_flow.
from collections import namedtuple
class Flow(list):
Entry = namedtuple('Entry', ['direction', 'data', 'offset'])
SENT = 'sent'
RECEIVED = 'received'
DIRECTIONS = [SENT, RECEIVED]
def __init__(self, filename):
with file(filename, 'r') as flow_file:
list.__init__(self, load_flow(flow_file))
This load_flow got a file object, which it used as an iterator, returning
each line of the input file. It got mapped using imap to regular expression
match objects, and filtered using ifilter to ignore rows that didn't match.
In the body of the loop, all three match groups are parsed, and sanity checks
are performed on the offset to make sure to bytes were lost during parsing.
For this purpose, a dict is used, initialized to zeros before the loop,
and incremented after each row to measure the number of bytes read in both
directions.
from binascii import unhexlify
from itertools import imap, ifilter
def load_flow(flow_file):
offset_cache = {Flow.SENT: 0, Flow.RECEIVED: 0}
for m in ifilter(None, imap(FLOW_ROW_RE.match, flow_file)):
direction = Flow.SENT if m.group(1) == '' else Flow.RECEIVED
offset = int(m.group(2), 16)
data = unhexlify(NON_HEX_RE.sub('', m.group(3)))
last_offset = offset_cache[direction]
assert last_offset == offset
offset_cache[direction] = last_offset + len(data)
The rest of the function is some code that (as of 14 March 2013) needs some
cleaning, and handles yielding Flow.Entry objects properly, squashing
entries spanning multiple rows at the same time.
As I mentioned in the beginning, there were two kinds of functionality I
needed, both of which use these Flow objects as an input. The first one
is a fake client/server that makes it possible to generate network traffic
quickly by using previously captured flows, called flowfake. It simply
replays flows from a selected viewpoint using plain sockets, either as
a client or a server.
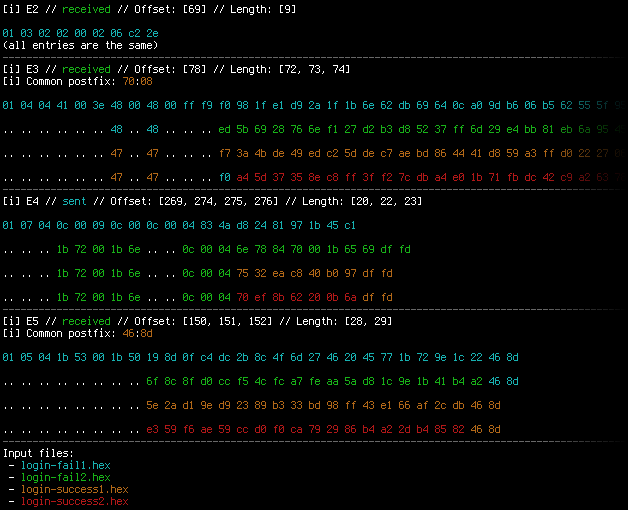
The second one is more interesting and complex (at least for me) as it makes possible to view the differences (or similarities, depending on the use-case) between 2 to 4 flows (latter being an ad-hoc limit based on the colors defined) using simple algorithms and colors to aid visual analysis. For better understanding, see the screenshot below to understand how it works on four flows. The whole project is available under MIT license in a GitHub repo.